HHVM 3.25 is released! This release contains new features, bug fixes, performance improvements, and supporting work for future improvements. Packages have been published in the usual places.
Additionally, we are releasing 3.24.4 and 3.21.8 which address CVE-2018-6332, but do not include the other changes listed below.
Highlights of 3.25 include:
- CVE-2018-6332: A potential denial-of-service issue in the Proxygen handling of invalid HTTP2 settings which can cause the server to spend disproportionate resources. This affects all supported versions of HHVM (3.24.3 and 3.21.7 and below) when using the proxygen server to handle HTTP2 requests.
- The PHP7
Throwable, Error, and Exception hierarchy is now always present, including in Hack and in PHP5 mode - however, internals will not raise instances of Error or subclasses if PHP5 mode is enabled.
- We intend to remove the ODBC extension in the next release - it has previously only been available when building HHVM from source. Please let us know via GitHub issues if this is important to you.
- Fixed a crash when closing cURL handles from inside a cURL callback
- The Visual Studio Code Debug Adapter Protocol is now supported in addition to hphpd and XDebug, and is our recommended debug interface. Support for the XDebug protocol will be removed in a future release.
- PHP7: PHP7 mode is now the default; PHP5 mode is still available, but unsupported.
- PHP7: Visibility modifiers on constants (PHP 7.1) will no longer raise a parse error, however they will be ignored
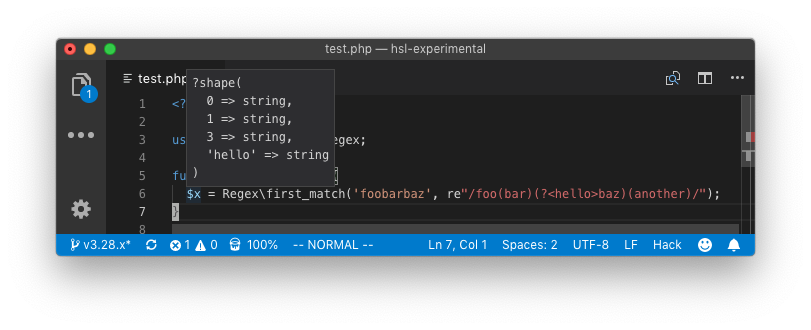
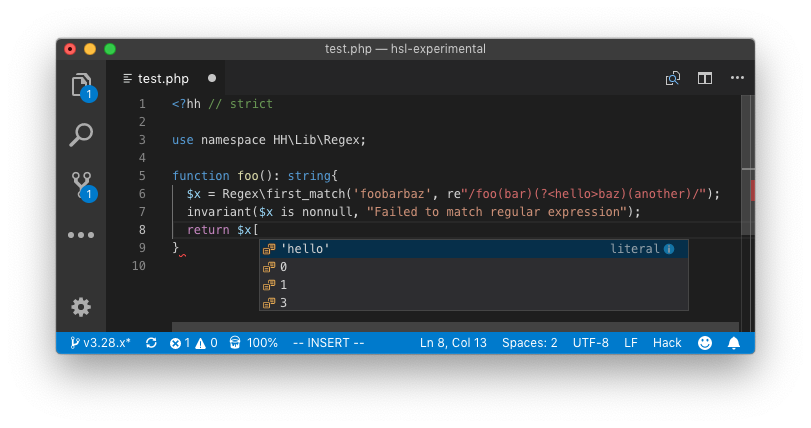
- PHP7 and Hack: Several more kinds of expressions are now permitted as callable; these were previously understood by the Hack typechecker, but not supported by the runtime.
- Hack:
inout function parameters are now supported, to replace references.
- Hack: typechecker errors are no longer converted to runtime errors by default, as it creates problems for tools that aim to resolve typechecker errors. For code that has typechecker errors, the behavior of the runtime remains undefined. You can restore the previous behavior with the
hhvm.hack.lang.auto_typecheck=1 ini setting.
- Hack: variadics without a variable name (e.g.
foo(...) { bar(func_get_args()); }) are no longer supported in strict mode. Use named variadics and splats instead (e.g. foo(string ...$args) { bar(...$args); }).
- Hack: variable variables (
$$foo) are no longer supported in decl mode.
- Hack: fixed several cases of double-nullable types (
??T) being inferred when using await.
- Hack: user-land implementations of Awaitable are no longer possible; this was previously undocumented and unsupported.
- Hack: the
array, array<Tv>, and array<Tk, Tv> types are no longer interchangeable. To ease migration, you can currently opt-out of this by setting safe_array=false and safe_vector_array=false in your .hhconfig, however we expect to remove this option in a future release.
- Hack: several additional features are available as opt-in, which we expect to be mandatory in 3.26; see the “Opt-In Typechecker Features” section below for details.
- Hack: an HHI file has been added for the PostgreSQL extension.
- Mac: resolved several race conditions that could lead to
hh_client hanging after spawning a server, or if it ran shortly after a server was started.
- Mac: the PostgreSQL extension is now included in our binaries.
inout Parameters
Hack inout parameters are a replacement for PHP references, aiming to remove confusing corner-cases and make additional performance improvements possible.
inout parameters allow local data to flow in and out of a function call. Changes to the data in the body of the function become visible to the caller after control returns.
1
2
3
4
| function f(inout int $var): void {
var_dump($var);
$var = 42;
}
|
Calling f() as follows,
1
2
3
| $x = 0;
f(inout $x);
var_dump($x);
|
will result in the output:
In the scope containing $x, the call to f() causes $x to be overwritten with a new value immediately after the call finishes execution.
HOW CAN I USE IT?
To declare a parameter as inout, add the inout keyword before the type annotation. If there is no type annotation, add it before the variable name.
1
2
3
| function g(int $x, inout string $y): void {...}
// Untyped - invalid in strict mode, discouraged in other modes:
function h(inout $z) {...}
|
When calling a function with one or more inout parameters, the corresponding arguments also need to be preceded by the inout keyword so that the calling convention is apparent.
1
2
3
4
| $s = 'foo';
g(42, inout $s);
h(inout $s[1]);
h($s[1]); // typechecker error, inout expected
|
When designing inout we wanted to ensure the feature is performant and behaves intuitively, so we added some additional restrictions:
- Arguments for
inout parameters are local variables with an arbitrary number of index expressions allowed.
- In other words, they should be local variables (
$x) or indexed elements contained inside a local ($vec[$y][z()][2]).
- The local cannot be a global or static.
- Every intermediate base in the index chain should also be a value-typed container (e.g. vec, dict, keyset, or array).
- Some types of functions cannot have
inout parameters, though support might be added in the future. Right now, these include class constructors, async functions, and generators.
- You cannot mix
inout parameters and PHP references (&) when defining or calling a function.
inout parameters cannot have default values or be variadic.- Currently, functions with
inout parameters cannot be memoized.
- If two expressions alias each other or otherwise refer to shared state, and one of those appears as an
inout argument, the other should not be used in a write context within the same statement.
- Examples are
swap(inout $a, inout $a[0]) and $a = h(inout $a[0]).
- This is unsupported and we leave its behavior undefined.
WHAT ARE THE SEMANTICS?
inout parameters have “copy-in copy-out” behavior.
- The argument’s value is copied into the function when it is called.
- The body of the function can make arbitrary changes to the copy.
- As the function returns, the value of the copy is assigned back to the argument from 1).
inout parameters look a lot like PHP references, but there are some key differences.
- Mutating an
inout parameter within a function does not instantly update the variable that was passed into the call.
- Those changes cannot be observed unless and until the call terminates normally.
- If an exception is thrown and not caught by the function, no values for any
inout parameters are copied out.
inout parameters are designed to be sound in Hack from day 1. They are fully supported in strict mode.
- With
& references, the type checker is ignorant of their semantics. It cannot warn if types become fluid as a result of multiple references to the same variable.
- Many syntactical constructs in PHP implicitly contain referencing mechanisms; however, all uses of
inout are required to be explicit, at both the declaration as well as the callsite.
SYNTACTIC SUGAR
Any function definition with inout parameters is transformed by the compiler so that it returns the final values of its inout parameters in addition to the function’s return value (if any). At the callsite, the new values returned for the inout parameters are assigned back to their initial arguments.
A function bar taking one or more inout parameters, and corresponding call to bar():
1
2
3
4
5
| function bar(inout Ta $a, Tb $b, ..., inout Tz $z, ...): Tr {
... // implementation, possibly changing $a and/or $z
return $ret;
}
$bar = bar(inout <A>, <B>, ..., inout <Z>, ...);
|
(with <A> etc. representing expressions) is roughly equivalent to:
1
2
3
4
5
| function bar(Ta $a, Tb $b, ..., Tz $z, ...): Tr {
... // implementation, as above
return tuple($a, $z, $ret);
}
list(<A>, <Z>, $bar) = bar(<A>, <B>, ..., <Z>, ...);
|
where <A> and <Z> are only evaluated once to compute parameter names and offsets for read/write.
I WANT A REAL-WORLD EXAMPLE!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| /**
* Extends a vec by appending the elements of the Traversable in-place.
*/
function extend<Tv>(
inout vec<Tv> $vec,
Traversable<Tv> $traversable,
): void {
foreach ($traversable as $value) {
$vec[] = $value;
}
}
$v = vec[3, 2, 1];
extend(inout $v, keyset[4, 5]);
var_dump($v); // vec[3, 2, 1, 4, 5]
|
Visual Studio Code Debug Adapter Protocol Support
HHVM now supports debugging via the Visual Studio Code Debug Adapter Protocol, which will be replacing use of XDebug for debugging in the next release. The VS Code protocol offers a more modern and extensible feature set and the switch allowed us to fix several significant issues in the HHVM debugger back-end that were fundamentally broken due to use of XDebug. Documentation for this protocol can be found here: https://code.visualstudio.com/docs/extensionAPI/api-debugging
With this, HHVM now offers a completely new debugging engine back-end, which will prove to be faster, more reliable, and will allow us to iterate and build better debugging experiences much more effectively. Switching to the VS Code protocol aligns with our new support for Hack language services via the VS Code Language Server Protocol. Additionally, the VS Code debug protocol is part of a sizable and growing ecosystem that is well supported by several great open source projects.
The new HHVM debugger is compatible with IDEs that speak the VS Code Debug Adapter protocol including Nuclide and Visual Studio Code. This debugger will be replacing the existing XDebug-based HHVM debugger. **Note that this means support for the XDebug protocol is now deprecated, and will be removed completely in the next release of HHVM. **We are currently planning to replace hphpd in the near future with a new CLI debugging experience that is compatible with all VS Code debuggers, including HHVM, but will keep hphpd in place and supported until the replacement is ready.
Enabling The New Debugger
Like HHVM’s other debuggers, this new debugger is disabled by default when HHVM is running in server mode. To enable it, set vs_debug_enable = true in your config file:
hhvm.debugger.vs_debug_enable=1
When enabled, in server mode the debugger will listen for incoming connections on TCP port 8999 by default. This can be overridden in your config file as well:
``hhvm.debugger.vs_debug_listen_port=<port>
To support debugging scripts, HHVM now accepts some new command line parameters:
1
| hhvm --mode vsdebug --vsDebugPort <port> <... other args> <your_script.php>
|
This will execute the specified script with the new debugger enabled. On startup, HHVM will stop and wait for a debugger to connect on the specified port before beginning execution of the script. Compatible IDEs such as Nuclide will offer a way to attach to hhvm on the specified port and begin execution and debugging of the script.
It is also possible to begin running a script in a mode that allows the debugger to attach and break in later:
1
| hhvm --mode vsdebug --vsDebugPort <port> --vsDebugNoWait true <...> <your_script.php>
|
This command is similar to the previous one, except HHVM will not wait for the debugger on startup. Instead it will begin executing your script immediately as normal, but it will accept a connection from your debugger on the specified port. The debugger can attach later and break into the target. This is useful for being able to break into long-running scripts that need to be debugged after executing for a while. Nuclide will offer a mechanism to list scripts started in this fashion and break in to them.
Support for connecting to the new HHVM debugger via Visual Studio Code is available via open source VS Code extensions, such as https://github.com/PranayAgarwal/vscode-hack
Upcoming Hack Language Changes
These features are opt-in in 3.25, but we expect them to be mandatory in HHVM 3.26. These are all supported by the active libraries and tools available on https://github.com/hhvm/.
Removing Namespace Fallback for Functions and Constants
To improve consistency and remove ambiguity, we are removing the root-namespace fallback for functions and constants:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <?hh
namespace MyNS;
function main(): void {
// Always refers to \MyNS\MyClass();
new MyClass();
// Currently may refer to either \MyNS\my_func() or \my_func(), depending on what's
// available at runtime; in 3.26 and above, it will always refer to \MyNS\my_func()
my_func();
// Explicitly reference \MyNS\my_func():
namespace\my_func();
// Explicitly reference \my_func();
\my_func();
}
|
To enable this behavior in 3.25, set enable_experimental_tc_features = no_fallback_in_namespaces in your project .hhconfig file.
HHAST is able to automatically migrate codebases that have no other typechecker errors:
1
| hhast$ bin/hhast-migrate --no-namespace-fallback /path/to/your/project/
|
Verifying Arity of Variadic Function Calls
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <?hh
function foo(int $first, int...$rest): void {}
// In 3.25, this is permitted, however it is unsafe as $args may be empty. We expect
// to ban this in 3.26.
function bar(int ...$args): void {
foo(...$args);
}
// Instead:
function bar(int $first, int ...$rest): void {
foo($first, ...$rest);
}
|
Tuples are still permitted if they have sufficient elements of the correct types, for example:
1
2
3
| function bar((int, int) $args): void {
foo(...$args);
}
|
To enable this behavior in 3.25, set enable_experimental_tc_features = unpacking_check_arity in your project .hhconfig file.
Banning Destructors
We are removing destructors from Hack to simplify behavior and remove the need for strict reference counting in the runtime; common approaches to replace them include:
- Disposables (introduced in HHVM 3.24)
- try/catch/finally constructs
register_shutdown_function()
To enable this behavior in 3.25, set disallow_destruct = true in your project .hhconfig file.
Destructors can also be banned at runtime by setting the hhvm.allow_object_destructors= false HHVM INI setting, though this will also affect PHP files.
Banning References In/To Arrays
PHP references are completely banned in strict mode, however they’re currently permitted in partial mode. While we’re not yet changing that, we are banning them inside arrays:
1
2
3
4
5
6
7
| <?hh
function foo(): void {
$x = array(42);
// Will be banned in 3.26:
$z = &$x[0];
}
|
To enable this behavior in 3.25, set enable_experimental_tc_features = disallow_refs_in_array in your project .hhconfig file.
Banning Passing Untyped Lambdas As Non-Function Types In Strict Mode
1
2
3
4
5
6
7
8
9
| <?hh // strict
function foo(mixed $f): void {}
function bar(): void {
// Inference can't be used if passing untyped, so this is unsafe, and will be
// banned in 3.26
foo($a ==> $a);
}
|
To enable this behavior in 3.25, set enable_experimental_tc_features = disallow_untyped_lambda_as_non_function_type in your project .hhconfig file.