
HHVM 3.22
HHVM 3.22 is released! This release primarily contains bug fixes, performance improvements, and supporting work for future improvements. Packages have been published in the usual places; see the installation instructions for more information.
Noteworthy changes include:
- The typechecker is now aware that
asyncis not valid in interfaces; this would previously be a runtime error. This is becauseasyncis an implementation detail: what matters for interfaces and abstract functions is that the function returns anAwaitable. - Allow trailing commas in group use statements; this fixes an incompatibility with hackfmt
- Added ‘throw’ option to
unserialize(), to throw an exception instead of returning a__PHP_Incomplete_Classwhen using a whitelist and the class isn’t whitelisted; this is especially useful when the problem is nested. - Added nested indexing support for the
??operator (e.g.$nullable_container[0][1][2] ?? null) to the Hack typechecker - Our docker images now include git, wget, and curl. This should allow most composer-based projects to install dependencies without needing to use apt, reducing image build times. We’ve applied the same change to the updates for 3.18 and 3.21.
- Security improvements (also in 3.18.5 and 3.21.3):
- Fix potential crash in PCRE cache
- Fix potential out-of-bounds read on invalid inputs to nl_langinfo()
- Fix a use-after-free in ext_domdocument
- Fix overflow checks in mbfl_memory_device
- Fix potential segfault in mb_strcut
Introducing HHAST
Abstract syntax trees can be an extremely powerful basis for many kinds of tooling beyond compilers and optimization; HHAST is a new framework, built on top of Hack’s Full Fidelity Parser (FFP), providing a Hack object representation of a mutable AST. Unlike traditional ASTs, the FFP’s AST includes all ‘trivia’ - such as whitespace and comments - allowing you to fully recreate the file from the AST, or create an updated file after mutating the AST, preserving comments and whitespace.
HHAST has 3 main APIs:
- A low-level library for inspecting and manipulating the FFP AST
- A linting framework, with support for auto-fixing linters
- A migration framework
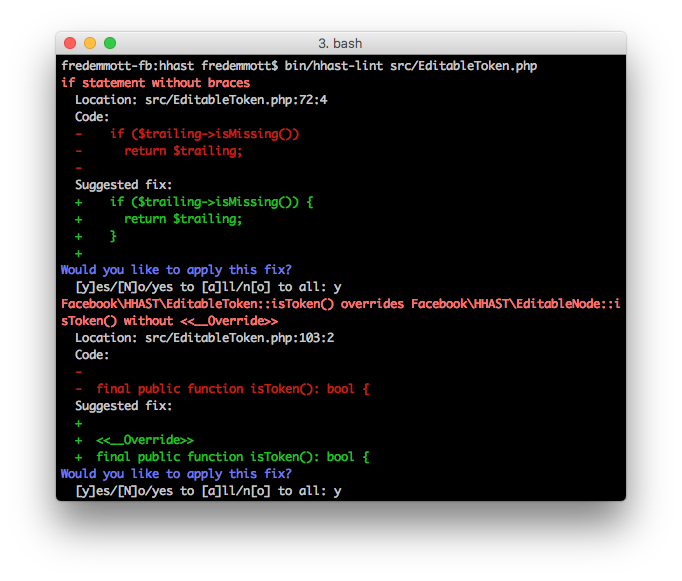
Linters
Linters are designed for subjective or style changes which do not substantially alter the behavior of the code, and may be rejected on a case-by-case basis. Lint errors can provide a suggested fix, which may be based on an AST mutation, but doesn’t have to be.
We’ve included several linters as a starting point, including:
- Don’t use
awaitin a loop - Methods should be
->lowerCamelCase(), functions should beunder_scored() - Always use braces for control flow
- Always use
<<__Override>>where possible
Linters can be used both interactively, or unattended. Autofixing is not supported unattended, however it will exit with non-zero if there are any lint issues, to ease integration with CI systems.
Migrations
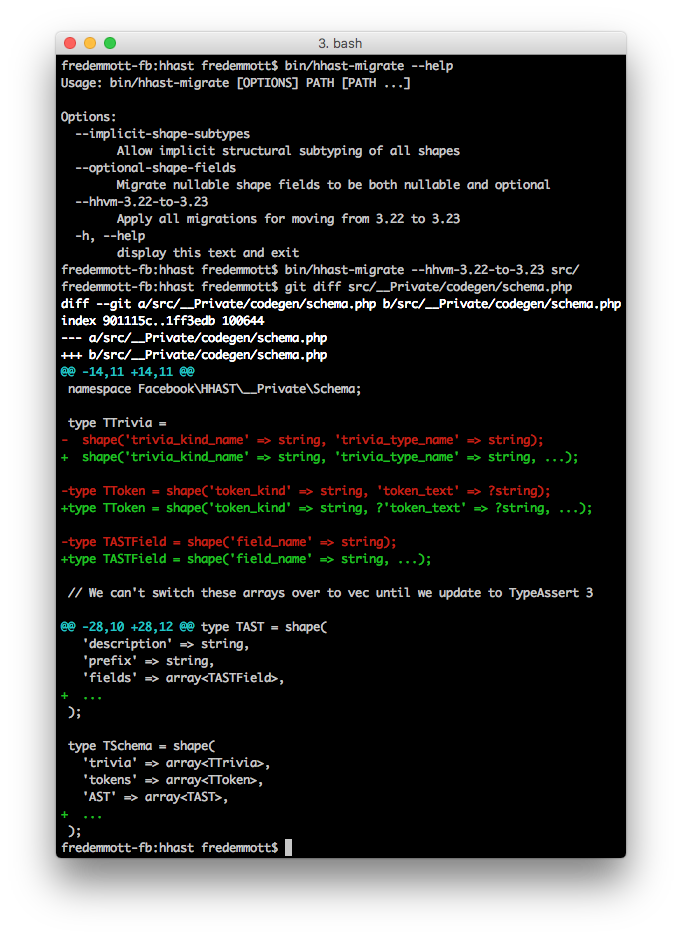
Migrations are for sweeping changes you want to apply across your entire codebase, and are often more complex. Taking this into account, the migration framework has built-in support for multi-step migrations (unlike linters). AST-aware migrations can be a powerful tool for:
- adjusting for changes to the language (for example, the shape changes described below)
- replacing deprecated APIs with new ones
- general clean-up of the codebase
Upcoming Changes
Nullable vs optional fields in shapes
Currently, nullable fields in shapes can be omitted, and shapes implicitly support structural subtyping - that is, if shape A has all the required fields of shape B, it is a subtype of shape B, even if it also has extra ones. This can lead to bugs - for example:
1
2
3
4
5
6
7
8
9
10
11
<?hh
type MyShape = shape('myfield' => ?string);
function foo(MyShape $_): void {
}
function main(): void {
// As MyShape has no required fields, we're passing
// in a valid subtype of it here, so this is fine
foo(shape('myfiedl' => 'oops I typoed'));
};
We are addressing this by:
- making structural subtyping opt-in per shape type
- making a distinction between nullable and optional shape fields
The existing syntax for nullable shape fields will continue to mean that they are nullable, but that they are required; fields can be made optional by prefixing the field name with ?:
1
2
3
4
5
6
7
<?hh
type MyShape = shape(
'nullable' => ?string,
?'optional' => string,
?'nullableAndOptional' => ?string,
);
To allow structural subtyping, add ... at the end of the field list:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
<?hh
type NoImplicitSubtypes = shape(
?'foo' => string,
);
type ImplicitSubtypes = shape(
?'foo' => string,
...
);
function foo(NoImplicitSubtypes $_): void {}
function bar(ImplicitSubtypes $_): void {}
function main(): void {
foo(shape('fo' => 'bar')); // hack error
bar(shape('fo' => 'bar')); // valid
}
So, you can migrate your code by:
- prefixing the name of all optional fields with
? - adding
...to the end of all your shape definitions
In HHVM 3.22, you can experiment with these changes by setting enable_experimental_tc_features = optional_shape_field, unknown_fields_shape_is_not_subtype_of_known_fields_shape in your projects’ .hhconfig file. We expect to make this behavior opt-out in HHVM 3.23, and remove support for opting out in HHVM 3.24. The unknown_fields_shape_is_not_subtype_of_known_fields_shape option requires the optional_shape_field to take effect.
We realize that adapting could be a substantial amount of work; to help, we are including a migration script with HHAST to make these changes for you:
array, array<T>, and array<Tk, Tv>
In a future release, we expect the typechecker to stop considering array<T> a subtype of array (without generics), and for array<Tk, Tv> to stop being considered a subtype of either array or array<T>. For example, every function call below will be a type error:
1
2
3
4
5
6
7
8
9
10
11
12
<?hh
function foo(array $data): void {
bar($data);
baz($data);
}
function bar(array<string> $data): void {
baz($data);
}
function baz(array<int, string> $_): void
This is primarily to avoid bugs caused by passing array<int, Tv> to functions that take array<Tv>, which can lead to confusion as to whether the keys are important or not. array (without generics) is also changed as otherwise it would leave the possibility for these accidental errors, as it is effectively the union type of array<_> and array<_, _>.
We are likely to roll this change out on a more aggressive timeline than the shapes changes above, as once code is updated to be compatible with this change, it will continue to be able to run on older versions of HHVM. If you want to test with this feature or work on compatibility in advance, you can set the following flags in your project’s .hhconfig:
safe_vector_array = true: disablearray<Tv>andarray<Tk, Tv>interoperabilitysafe_array = true: disablearrayinteroperability with botharray<T>andarray<Tk, Tv>
These options are experimental and will be removed in a future release of HHVM, so we don’t recommend committing them to projects that target multiple versions of HHVM.
Hack arrays and The Hack Standard Library
Once the Hack Standard Library reaches v1.0 (currently expected before the HHVM 3.23 release), Hack Arrays (vec<T>, dict<Tk, Tv>, and keyset<T>) will become the recommended collections in Hack. Over time, changes will include:
- Hack libraries under github.com/hhvm/ and github.com/facebook/ changing to accept hack arrays, and either return hack arrays or generic interfaces such as
Traversable<T>orKeyedTraversable<Tk, Tv>. - Similar changes to HHVM-specific builtins, such as the async MySQL extension
- Tuples are likely to become backed by
vecs, and shapes are likely to become backed bydicts.