
Wikipedia on HHVM
If you’ve been watching our GitHub wiki, following us on Twitter, or reading the wikitech-l mailing list, you’ve probably known for a while that Wikipedia has been transitioning to HHVM. This has been a long process involving lots of work from many different people, and as of a few weeks ago, all non-cached API and web traffic is being served by HHVM. This blog post from the Wikimedia Foundation contains some details about the switch, as does their page about HHVM.
I spent four weeks in July and August of 2014 working at the Wikimedia Foundation office in San Francisco to help them out with some final migration issues. While the primary goal was to assist in their switch to HHVM, it was also a great opportunity to experience HHVM as our open source contributors see it. I tried to do most of my work on WMF servers, using HHVM from GitHub rather than our internal repository. In addition to the work I did on HHVM itself, I also gave a talk about what the switch to HHVM means for Wikimedia developers.
Most of my time at Wikimedia was spent working on some fixes for HHVM’s DOMDocument support. MediaWiki, the software powering Wikipedia, allows users to import and export articles as XML files. To do this, it uses a custom PHP stream wrapper, which our implementation of DOMDocument didn’t properly support. We had a number of outstanding pull requests in this area, including a large one from from WMF developer Tim Starling. The main problem blocking its merge was a potential security issue: the default PHP settings allow XML external entity injection attacks, which we didn’t want to allow in HHVM. I combined the pending pull requests, cleaned them up a little, and implemented a protocol whitelist for external entities, keeping HHVM secure by default with the option to open things up if necessary. This is a good example of our general philosophy on PHP compatibility: we try to match PHP behavior exactly, unless doing so causes significant security issues or other problems.
We also spent a good amount of time debugging an issue with MediaWiki’s Lua scripting extension. This extension is compatible with both PHP 5.x and HHVM thanks to our Zend compatibility layer; if you’re thinking of switching to HHVM but have some native extensions you depend on, this is a great example to follow. The Lua library used by their extension is written in C and uses setjmp and longjmp to handle errors. In certain situations this was causing a number of C++ object destructors to be skipped, leading to memory corruption. Luckily, there was an easy fix once we figured out what was happening: when built as C++ code, the Lua library uses C++ exceptions instead of setjmp/longjmp, calling the appropriate destructors as the stack is unwound.
Once we had the correctness issues under control, I spent some time looking at HHVM’s performance on the MediaWiki workload. We’ve put a lot of engineering time into making HHVM fast, but most of that work has been on the PHP that powers Facebook. Like any large codebase, Facebook’s PHP code contains recurring idioms and design patterns, and HHVM is great at optimizing these. Looking at HHVM’s performance in the context of another large codebase, with its own recurring idioms and design patterns, was a great way to identify optimization opportunities we hadn’t yet discovered. I found two easy wins, the first of which was simply that the default Ubuntu PCRE package didn’t have the JIT enabled. We rebuilt PCRE with the JIT option enabled, which HHVM knows how to take advantage of, and saw a 8% improvement in the parsing benchmark.
The other tweak was also quite simple. PHP classes can have destructor functions that are run when instances of that class are destroyed, even if that only happens at the very end of the request because the object was kept alive by a global variable or a cyclic reference. Exactly matching PHP’s behavior here requires a small but measurable amount of extra bookkeeping at runtime, so HHVM has an option to not run destructors for objects that are alive at the end of a request. This is fine for PHP codebases like Facebook’s, where the application was written with this restriction in mind. MediaWiki, however, was developed using the standard PHP interpreter, so for correctness it should be run in the slower but more correct configuration. Since we weren’t using this configuration internally it wasn’t optimized very heavily, and I was able to improve the wikitext parser benchmark by another 4% with this commit. I then followed that up with another commit to make HHVM compatible by default, requiring anyone who needs that last bit of extra performance to opt into it.
While the Wikimedia Foundation blog post linked above has a complete picture of the performance gains they saw, we have a brief summary here as well. One important fact to keep in mind while while interpreting these results is that they were migrating from a fairly old version of PHP: 5.3. PHP 5.6 has some substantial performance improvements over 5.3, so the bump from PHP 5.6 to HHVM would likely be less dramatic. That said, switching all API/web servers over to HHVM is by no means the end of this process. There are a number of other tweaks that can be made to further improve HHVM’s performance, most notably using Repo Authoritative mode.
The first and most important graph shows the effect HHVM had on the experience for Wikipedia’s community of editors. While most page views on Wikipedia are served from a static cache without running any PHP, editing a page executes a lot of PHP and is one of the most expensive actions on the site. We were able to directly compare PHP 5.3 and HHVM during the transition, when some application servers were running PHP and some were running HHVM:
[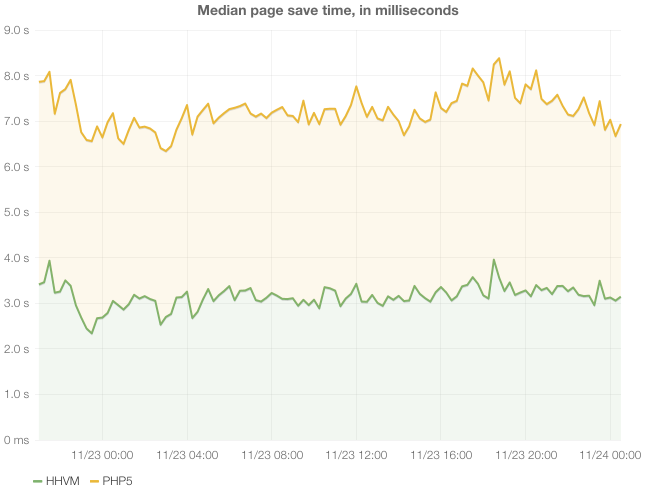
As you can see, the median page save time on the HHVM application servers was about 45% of PHP’s. This means that every time someone previews or saves an edit, they get the result back about twice as fast. And 7 seconds was just the median save time - there are lots of larger pages that used to take tens of seconds to save, even causing timeout errors in some extreme cases. These numbers look great but they don’t tell the whole story. Total page save time includes time spent waiting on the database (or any other IO), so the effects on CPU usage were even more pronounced. While reduced CPU usage doesn’t directly affect the user experience, it does reduce hardware costs by allowing a smaller number of servers to handle the same amount of traffic. Here’s a graph showing CPU usage of a random MediaWiki server, before and after it was converted to HHVM:
[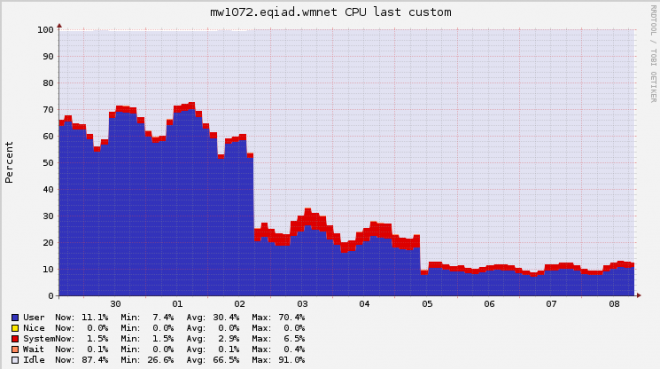
There are two clear steps downward: the initial switch to HHVM, and then a configuration tweak. The tweak was enabling the hhvm.server_stat_cache config option, which caches the results of stat calls and uses inotify to detect when files are changed. It’s hard to make any very precise claims about this graph since load varies with time of day and other factors, but by comparing daily peaks we can get some reasonable numbers. Peak CPU utilization dropped from about 70% to 12%, almost a 6x improvement.
Having free access to all of the knowledge contained in Wikipedia is an incredible resource for hundreds of millions of people around the world. Everyone on the HHVM team is excited to see our hard work helping out such an important project, and we’re optimistic about seeing even more performance gains in the future. The success of this transition is also a great indicator of the growing strength of the open-source community surrounding HHVM; Wikimedia developers Tim Starling, Ori Livneh, Erik Bernhardson, and Chad Horohoe all contributed a lot of work back to HHVM during the migration process.
Comments
- Kannan Goundan: "As you can see, the median page save time on the HHVM application servers was about 45% of PHP’s." It's actually kind of hard to see that since the y-axis doesn't start at zero. Please change the y-axis to start at zero.
- Maide: Very cool stuff! Congratulations to the Wikimedia and HHVN teams.
- Stefan Lenselink: Very cool to see al those improvements in terms of reduced response time (in most cases the ultimate goal). But could you tell something about the memory consumption? Most of the cases you will see a trade between cpu speed vs. Memory usage. My guess (I could be wrong) is that the memory usage increased, as nothing comes for free.
- hhvm-rocks: I have a question; Does hhvm.server.stat_cache=true setting help (as performance) to HHVM that runs under FCGI for function calls such as filemtime, filectime, is_file, is_dir, file_exists ? The answer is important for me since the kernel (3.10) supports inotify. (BTW, in the article; hhvm.server_stat_cache must be hhvm.server.stat_cache) Thanks :)
- Xandi Ostermeyr: Wow, congratulations! Amazing! Is there already an IDE Extension for PHPStorm or Netbeans?
- Radu Murzea: Wikipedia on HHVM... this is really cool. With their performance going up and their costs going down, this can be nothing but great news. Is it just me or is HHVM awesome ? :D
- Andrii Kasian: Will be great if anyone describe how to run big project (like magento2) in Repo Authoritative mode.
- Wikipedia reveals how Facebook’s hip hop can pep up PHP sites | Nagg: […] caveat to bear in mind however, according to Simmers[4], is part of the reason performance improvements were so pronounced was that the foundation was […]
- Joel Marcey: Graph has been updated.
- HHVM Blog: Wikipedia on HHVM - Reader: […] post to the HHVM blog, Brett Simmers looks at the recent announcement from Wikipedia and how they made the switch to HHVM and the impact it […]
- Fred Emmott: Sometimes - this really does change for each projects. Try both ways and see which is better for you. In master (and the next release) there are some optimizations that should make that family of functions (especially is_dir()) much faster.
- raxon1s: With the new PHPNG i don't think HHVM will make any difference at all, but anyway good job.
- hhvm-rocks: Thanks Fred ! You always help to the community by answering questions (at github, irc channel, here etc...). I respect your effort. "Try both ways and see which is better for you." Probably, I won't see the difference since we're talking about mili-seconds. But I added that setting and set that value to true. And thanks for the good news about is_dir() optimization, and also if you guys put some effort over file_exists function; it's very very much appreciated! In my application, there thumbnails (and boot script) that uses many file_exists. maybe (max) around 60 times per request. I think, there are many users who call file_exists functions many times in their applications. BTW, for include* and require* functions I use full path, and repo.auth=true , so they are just ok. I really really want to see some great optimizations for file_exists :) Thanks for all your (you and HHVM engineers) efforts..
- hhvm-rocks: I forgot to mention about benchmark. I will wait for the next release, and then will benchmark them to see; does it make sense... I tested a script at: http://3v4l.org/W9jkR/perf , that shows HHVM is outperformed by Zend for file_exists(). Maybe I should do the tests at my machine too. :?
- vijeesh: Congrats guys :) Gonna try it on one of our servers.
- Fred Emmott: In general, we don't work on optimizing functions until they show up as a bottleneck in a realistic open-source workload; for example, we optimized is_dir() because it was well over half the time spent executing our Drupal benchmark.
- gokul: after reading this post . I would like to learn hhvm . From where do I start
- How Wikipedia Transitioned to HHVM | CloudBackupCheap.com: […] Simmers wrote on the HHVM blog: […]
- Wikipedia Pindah ke HHVM: […] Brett Simmers dari tim HHVM menuliskan pengumuman ini diblog HHVM. […]
- A(nother) new era of WordPress – Be the signal: […] Want to strap a rocket to your WordPress platform? I strongly recommend experimenting with HHVM, if not putting it into production… like, say, Wikipedia. […]
- PHP updates from 2014. Hello Hack and HHVM! - Nitin Nain: […] for (uncached) page requests while drastically reducing the Load on their CPUs from 50% to 10%. Here are few more details on how Wikipedia’s move from zend to HHVM was carried […]
- Magento 1.9.1.0 – Page load time below 0.3s? | NEWSGENTO: […] very interesting case “Wikipedia on HHVM” shows 45% increase in efficiency compared to PHP5 in the production […]
- Wikipedias Wechsel zu HHVM: Welche Arbeit dahinter steckt - entwickler.de: […] Wikipedia, deren APIs und Web-Traffic nun komplett auf den von HHVM angetriebenen Servern liegen. In einem Blogpost im HHVM-Blog gibt Brett Simmers einige Einblicke in die Arbeit, die in den Umzug gesteckt […]
- A Chat With Drew Paroski, Co-Creator of HHVM and Hack - Application Performance Monitoring Blog | AppDynamics: […] ended up virtually loaning a developer to help with converting Wikipedia to HHVM. “One of the engineers on the HHVM team spent a great deal of time with Wikimedia, helping […]