
Faster and Cheaper: The Evolution of the hhvm JIT
When the hhvm project was started almost 4 years ago, it had a two-part mandate: First, create a PHP JIT that could serve facebook.com at least as efficiently as hphpc, the PHP execution engine we were using at the time. Second, replace hphpi, the interpreter our PHP developers were using in their daily work. hphpc and hphpi were independent pieces of software with unintentional subtle differences in behavior and a significant maintenance burden. Unifying the execution engines used in production and development would make our jobs easier while giving the PHP devs a nicer experience at the same time. We had to find a balance between reaching these goals as quickly as possible and designing a system that could be extended and improved for many years after it replaced hphpc and hphpi. There were also concerns that just in time compilation might not be fast enough to keep up with Facebook’s aggressive deployment process. We were pushing a new version of the site to our fleet of web servers once every weekday, and the whole process took less than 20 minutes. We had to maintain that ability for hhvm to be a viable option. Taking all this into account, the initial JIT design was the simplest and fastest one that we thought had a good chance of succeeding.
If you’re not familiar with the general architecture of hhvm, you might want to read through this post before continuing. Most of the JIT’s functionality ended up in a C++ class named TranslatorX64. We often use “translation” to refer to the process of converting a sequence of bytecode instructions (a tracelet) into an equivalent sequence of x86-64 instructions (a translation). Once we’ve selected a tracelet to translate, TranslatorX64 walks through it and emits machine code for each bytecode as a self-contained unit. We knew that by doing this we would miss out on many cross-bytecode optimization opportunities, but this approach would be much simpler to implement. More importantly, we had some microbenchmark results suggesting that this would be good enough to beat hphpc. In the end, this approach was almost enough to get the job done.
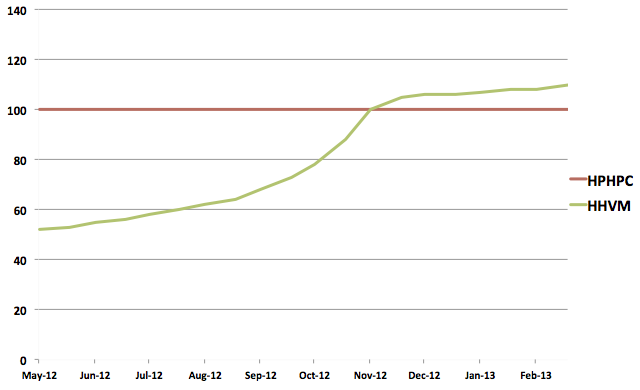
As the summer of 2012 was drawing to a close, hhvm still wasn’t competitive with hphpc and we didn’t have a solid plan to change that. The project was over 2 years old by then, and we knew that if we didn’t beat hphpc soon we’d have to seriously reconsider hhvm’s future. The fact that hphpc had gotten about twice as fast since hhvm’s birth didn’t help either (though it was great news for our web servers). We went into lockdown to throw everything we had at hhvm and push it across the finish line. After a few months of working hard we comfortably beat our goal, pushing hhvm to be 10% faster than hphpc. There wasn’t one big optimization that got us there; we just kept chipping away at it by making lots of small improvements like reducing cache misses, reducing code size, taking advantage of statically inferred type information, and many other tweaks. The success of hhvm was inevitable at that point, but to make it as far as we had, we needed to hack up a few of those cross-bytecode optimizations we thought we could avoid for the first iteration of the JIT. Since TranslatorX64 wasn’t designed to support these optimizations, the code became increasingly more complicated and hard to work with. It was clear that while TranslatorX64 got us past the first finish line, it probably wasn’t going to be enough for the future improvements we had in mind. Here’s a chart of our progress (as a percentage of hphpc’s efficiency) from mid 2012 to February 2013, when hphpc was completely retired:
Since we’re software engineers, we solved this problem by adding a new layer of indirection. This new layer is an SSA form intermediate representation, positioned between the bytecodes in TranslatorX64’s tracelets and the x86 machine code we want to end up with. It’s strongly typed and designed to facilitate a number of optimizations we wanted to port from TranslatorX64 as well as new optimizations in the future. This new IR, named hhir (short for HipHop Intermediate Representation), completely replaced TranslatorX64 as hhvm’s JIT in May of 2013. While hhir specifically refers to the representation itself, we often use the name to refer to all the pieces of code that interact with it. If you’ve looked at our source code recently you might have noticed that a class named TranslatorX64 still exists and contains a nontrivial amount of code. That’s mostly an artifact of how the system is designed and is something we plan to eventually clean up. All of the code left in TranslatorX64 is machinery required to emit code and link translations together; the code that understood how to translate individual bytecodes is gone from TranslatorX64.
When hhir replaced TranslatorX64, it was generating code that was roughly 5% faster and looked significantly better upon manual inspection. We followed up its production debut with another mini-lockdown and got an additional 10% in performance gains on top of that. To see some of these improvements in action, let’s look at a function addPositive and part of its translation.
1
2
3
4
5
6
7
8
9
10
11
function addPositive($arr) {
$n = count($arr);
$sum = 0;
for ($i = 0; $i < $n; $i++) {
$elem = $arr[$i];
if ($elem > 0) {
$sum = $sum + $elem;
}
}
return $sum;
}
This function looks like a lot of PHP code: it loops over an array and does something with each element. Let’s focus on lines 5 and 6 for now, along with their bytecode:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$elem = $arr[$i];
if ($elem > 0) {
// line 5
85: CGetM <L:0 EL:3>
98: SetL 4
100: PopC
// line 6
101: Int 0
110: CGetL2 4
112: Gt
113: JmpZ 13 (126)
These two lines load an element from an array, store it in a local variable, then compare the value of that local with 0 and conditionally jump somewhere based on the result. If you’re interested in more detail about what’s going on in the bytecode, you can skim through bytecode.specification. The JIT, both now and back in the TranslatorX64 days, breaks this code up into two tracelets: one with just the CGetM, then another with the rest of the instructions (a full explanation of why this happens isn’t relevant here, but it’s mostly because we don’t know at compile time what the type of the array element will be). The translation of the CGetM boils down to a call to a C++ helper function and isn’t very interesting, so we’ll be looking at the second tracelet. This commit was TranslatorX64’s official retirement, so let’s use its parent to see how TranslatorX64 translated this code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
cmpl $0xa, 0xc(%rbx)
jnz 0x276004b2
cmpl $0xc, -0x44(%rbp)
jnle 0x276004b2
101: SetL 4
103: PopC
movq (%rbx), %rax
movq -0x50(%rbp), %r13
104: Int 0
xor %ecx, %ecx
113: CGetL2 4
mov %rax, %rdx
movl $0xa, -0x44(%rbp)
movq %rax, -0x50(%rbp)
add $0x10, %rbx
cmp %rcx, %rdx
115: Gt
116: JmpZ 13 (129)
jle 0x7608200
The first four lines are typechecks verifying that the value in $elem and the value on the top of the stack are the types we expect. If either of them fails, we’ll jump to code that triggers a retranslation of the tracelet, using the new types to generate a differently specialized chunk of machine code. The meat of the translation follows, and the code has plenty of room for improvement. There’s a dead load on line 8, an easily avoidable register to register move on line 12, and an opportunity for constant propagation between lines 10 and 16. These are all consequences of the bytecode-at-a-time approach used by TranslatorX64. No respectable compiler would ever emit code like this, but the simple optimizations required to avoid it just don’t fit into the TranslatorX64 model.
Now let’s see the same tracelet translated using hhir, at the same hhvm revision:
1
2
3
4
5
6
7
8
9
10
11
12
13
cmpl $0xa, 0xc(%rbx)
jnz 0x276004bf
cmpl $0xc, -0x44(%rbp)
jnle 0x276004bf
101: SetL 4
movq (%rbx), %rcx
movl $0xa, -0x44(%rbp)
movq %rcx, -0x50(%rbp)
115: Gt
116: JmpZ 13 (129)
add $0x10, %rbx
cmp $0x0, %rcx
jle 0x76081c0
It begins with the same typechecks but the body of the translation is 6 instructions, significantly better than the 9 from TranslatorX64. Notice that there are no dead loads or register to register moves, and the immediate 0 from the Int 0 bytecode was propagated down to the cmp on line 12. Here’s the hhir that was generated between the tracelet and that translation:
1
2
3
4
5
6
7
8
9
10
(00) DefLabel
(02) t1:FramePtr = DefFP
(03) t2:StkPtr = DefSP<6> t1:FramePtr
(05) t3:StkPtr = GuardStk<Int,0> t2:StkPtr
(06) GuardLoc<Uncounted,4> t1:FramePtr
(11) t4:Int = LdStack<Int,0> t3:StkPtr
(13) StLoc<4> t1:FramePtr, t4:Int
(27) t10:StkPtr = SpillStack t3:StkPtr, 1
(35) SyncABIRegs t1:FramePtr, t10:StkPtr
(36) ReqBindJmpLte<129,121> t4:Int, 0
The bytecode instructions have been broken down into smaller, simpler operations. Many operations hidden in the behavior of certain bytecodes are explicitly represented in hhir, such as the LdStack on line 6 which is part of the SetL. By using unnamed temporaries (t1, t2, etc…) instead of physical registers to represent the flow of values, we can easily track the definition and use(s) of each value. This makes it trivial to see if the destination of a load is actually used, or if one of the inputs to an instruction is really a constant value from 3 bytecodes ago. For a much more thorough explanation of what hhir is and how it works, take a look at ir.specification.
This example showed just a few of the improvements hhir made over TranslatorX64. Getting hhir deployed to production and retiring TranslatorX64 in May 2013 was a great milestone to hit, but it was just the beginning. Since then, we’ve implemented many more optimizations that would be nearly impossible in TranslatorX64, making hhvm almost twice as efficient in the process. It’s also been crucial in our efforts to get hhvm running on ARM processors by isolating and reducing the amount of architecture-specific code we need to reimplement. Watch for an upcoming post devoted to our ARM port for more details!
Comments
- dawehner: We have december now, so it would be great to have the graph extended until now.
- Is Facebook Planning a Move to ARM Based Servers? | Joseph Scott: […] latest update from Facebook about the HHVM JIT ended with this interesting note, emphasis […]
- Brett Simmers: One of our other devs is working on a post about more recent perf improvements, so that should have newer graphs.
- Facebook hints at ARM server deployment too — Tech News and Analysis: […] it was rumors of Google building ARM-based servers, and now a post on the blog dedicated to Facebook’s HipHop Virtual Machine for PHP code notes how its translation engine plays a “crucial in our efforts to get hhvm running on ARM […]
- Facebook hints at ARM server deployment too | My Website: […] it was rumors of Google building ARM-based servers, and now a post on the blog dedicated to Facebook’s HipHop Virtual Machine for PHP code notes how its translation engine plays a “crucial in our efforts to get hhvm running on ARM […]
- Facebook hints at ARM server deployment too | 8ballbilliard: […] it was rumors of Google building ARM-based servers, and now a post on the blog dedicated to Facebook’s HipHop Virtual Machine for PHP code notes how its translation engine plays a “crucial in our efforts to get hhvm running on […]
- Facebook hints at ARM server deployment too | IT News: […] it was rumors of Google building ARM-based servers, and now a post on the blog dedicated to Facebook’s HipHop Virtual Machine for PHP code notes how its translation engine plays a “crucial in our efforts to get hhvm running on ARM […]
- Facebook hints at ARM server deployment too | Content Loop: […] it was rumors of Google building ARM-based servers, and now a post on the blog dedicated to Facebook’s HipHop Virtual Machine for PHP code notes how its translation engine plays a “crucial in our efforts to get hhvm running on ARM […]
- Facebook hints at ARM server deployment too | Earthgrid: […] it was rumors of Google building ARM-based servers, and now a post on the blog dedicated to Facebook’s HipHop Virtual Machine for PHP code notes how its translation engine plays a “crucial in our efforts to get hhvm running on ARM […]
- Facebook porting its PHP engine to ARM | High Performance Computing Info: […] the HHVM blog post and an article at The […]
- Programowanie w PHP » Blog Archive » HipHop Blog: Faster and Cheaper: The Evolution of the hhvm JIT: […] the HHVM (HipHop Virtal Machine) blog there’s a new post that looks at the evolution of the HHVM JIT compiler since the project started about four years […]
- : […] […]
- Facebook ใช้งาน HipHop VM เต็มตัว, ประสิทธิภาพดีกว่ารุ่น C++, เตรียมรันบน ARM | ข่าวล่าสุด: […] – HHVM, The […]
- Facebook PHP engine eyeing move to ARM server chips - Crutch Technologies: […] post on the Hip Hop Virtual Machine (HHVM) blog on Thursday indicated that the team there is implementing ARM processor support into its […]
- Facebook PHP engine eyeing move to ARM server chips | TechWorthy.info: […] post on the Hip Hop Virtual Machine (HHVM) blog on Thursday indicated that the team there is implementing ARM processor support into its […]
- Facebook PHP engine eyeing move to ARM server chips | Plugged Into The Matrix: […] post on the Hip Hop Virtual Machine (HHVM) blog on Thursday indicated that the team there is implementing ARM processor support into its […]
- Nowe Technologie | Google stworzy własne mikroprocesory na rdzeniach ARM?: […] właśnie swoje plany dotyczące wykorzystania procesorów z rdzeniami ARM ogłosił Facebook, informując, że bliski jest przeniesienia kompilatorów PHP na nową architekturę, a następnie publikując […]
- Facebook PHP engine eyeing move to ARM server chips | Techy News Today: […] post on the Hip Hop Virtual Machine (HHVM) blog on Thursday indicated that the team there is implementing ARM processor support into its […]
- Facebook hints at ARM server deployment too | VIGALUM: […] it was rumors of Google building ARM-based servers, and now a post on the blog dedicated to Facebook’s HipHop Virtual Machine for PHP code notes how its translation engine plays a “crucial in our efforts to get hhvm running on ARM […]
- Eltechs Facebook Considers Shift to ARM-based Servers: […] recent post on Hip Hop Virtual Machine (HHVM) blog indicates that the team works on implementing ARM support. HHVM is a Facebook’s PHP engine […]
- HHVM and Hack - Part 1 - SitePoint: […] HPHPc did a good job on improving performance but it was not without issues: maintaining both HPHPc and HPHPi in sync proved to be cumbersome plus some differences still existed between the transpiled code vs the interpreted one. That's why back in 2010 Facebook decided to go for another approach and created HHVM – a new virtual machine designed to replace the Zend Engine used by PHP. By the end of 2012 HHVM achieved performance parity with the former HPHPc and soon surpassed it. […]
- HHVM and Hack – Part 1 – Bruno Škvorc | WarWebDev: […] HPHPc did a good job on improving performance but it was not without issues: maintaining both HPHPc and HPHPi in sync proved to be cumbersome plus some differences still existed between the transpiled code vs the interpreted one. That’s why back in 2010 Facebook decided to go for another approach and created HHVM – a new virtual machine designed to replace the Zend Engine used by PHP. By the end of 2012 HHVM achieved performance parity with the former HPHPc and soon surpassed it. […]
- HHVM: The Next Six Months « HipHop Virtual Machine: […] set very aggressive efficiency goals for the half that we hope to achieve through a range of JIT compiler projects. We hope these translate into wins for a variety of PHP workloads. We’re shooting for […]
- Advanced Micro Devices, Inc. (AMD) news: My Best 2014 Catalyst For AMD Is … – Seeking Alpha | Home audio market: […] promise of very energy-efficient ARM-based server processors prompted Facebook engineers to make its HipHop Virtual Machine JIT compilation engine (which runs all of Facebook’s server farms) […]
- Limbajul de programare Hack, apocalipsa PHP? | Claudiu Persoiu: […] ruleaza pe HHVM. HHVM este incercarea Facebook de optimizare a limbajului PHP prin Just In Time complication, ultima abordare de optimizare a limbajului. Practic, Facebook incearca sa-si reduca din costuri, […]
- Ein halbes Jahr HHVM - entwickler.de: […] set very aggressive efficiency goals for the half that we hope to achieve through a range of JIT compiler projects. We hope these translate into wins for a variety of PHP workloads. We’re shooting for […]
- HHVM is not for WordPress – RokkiCH: […] beautiful and I like it for the administration simplicity and throughput benefits it offers. The JIT is performing better and better by each new release. This is absolutely brilliant if you’re […]