
Concurrent JIT Compilation
HHVM’s JIT is responsible for translating sequences of HipHop Bytecode (HHBC) into equivalent sequences of machine code in order to execute PHP code as efficiently as possible. When running in server mode, HHVM shares this generated code across the many different threads executing PHP requests. Up until about a year ago, the JIT had a global “write lease,” which prevented multiple threads from running the JIT concurrently. This decision was made primarily to improve the layout of the generated code, but also to reduce implementation complexity. The project was still unproven, and we had to balance between shipping a perfect system and never shipping anything.
The initial versions of HHVM’s JIT operated on small compilation units called “tracelets.” These were each no bigger than one basic block, and often quite a bit shorter. When attempting to execute a piece of code that had not yet been compiled, HHVM would compile one tracelet in the JIT, run that newly-compiled code, compile and run the next tracelet, and repeat this process until the whole program was compiled. Since we were breaking the source program up into many small pieces, we had to keep these pieces as close together as possible to keep the CPU’s instruction cache happy. We had two options: build support for relocating code after compilation, or emit it to the correct place the first time. We chose the latter option, and the write lease was the primary mechanism we used to accomplish this. We called it a “lease” rather than a “lock” because it was meant to be held for a long time: once a thread acquired the write lease, it would hold onto it until the end of its request. This ensured that no other threads would emit code between the end of one tracelet and the beginning of the next. And because only one thread was running in the JIT, we didn’t have to worry about making any of the core JIT data structures thread-safe.
After we added profile-guided optimizations to HHVM in 2014, our tracelet-induced code layout restriction was mostly gone. We use tracelets in the profiling gear, but the profiling code is only used transiently, meaning its layout doesn’t matter as much. With this restriction lifted, there were no fundamental design issues standing between us and running the JIT concurrently in different threads.
What was standing in the way was a big pile of tech debt. Since the JIT had been single-threaded since the beginning of the project, enormous swaths of code and global state implicitly relied on the current thread holding the write lease. We’d have to audit each piece of global state and figure out if it was actually process-global state, or if it was only relevant to the current compilation unit (also referred to as a “translation” in HHVM). Data in the former category would have to be given finer-grained locks than the global write lease, while the latter category would have to be pulled out of the global scope so each thread could have its own copy.
The next few sections discuss how we solved a few of these issues. If you’d rather look through a raw list of all the commits involved, that can be found here.
The Write Lease(s)
We decided that, while we wanted to have as few restrictions on concurrency as possible, we would only allow one translating thread per PHP function. This was for the benefit of profiling translations: the physical layout of the compiled code is not very important due to its transient nature, but we still needed to make sure each function was broken up into a logical and coherent set of profiling blocks. Since this partitioning depends heavily on the runtime behavior of the program and can’t be done ahead of time, the best way to accomplish this was by ensuring that each function never had more than one thread translating in it at any given time. We added function-specific write leases in this commit, which was the first time HHVM was capable of any amount of concurrent compilation.
This does put an upper limit on how much concurrency we can achieve in the JIT, but Facebook’s PHP codebase (and any other reasonably large codebase) is split up into many different small functions, so it’s not an issue in practice. We expect that unless you feed HHVM a small number of functions that are thousands of lines each, it shouldn’t cause any problems.
After adding function-specific locks, threads still had to grab the global write lease halfway through the translation process, before they could emit any machine code or modify any global data structures. This was further broken down by adding separate locks for the TC and metadata. The write lease was no longer necessary for controlling access to the JIT’s global data structures, and was only used when the JIT’s concurrent features were disabled.
The code and metadata locks do impose some serialization on the compilation process, so we added a limit on the number of threads that are allowed to execute in the JIT at any given time. This is primarily to reduce contention on these locks and has no effect on correctness. Setting the concurrency level too high causes so much contention that the server makes almost no progress at all, either in terms of requests served or code compiled. More recently, we’ve leveraged our code relocator to reduce the time spent holding these locks, which greatly increased the concurrency level we can achieve.
CodeGenFixups
While the main output of HHVM’s JIT is the compiled machine code, it also generates a sizable amount of metadata. This metadata includes the positions of calls that may throw exceptions (and how to handle those exceptions), code addresses that need to be aligned in certain ways, mappings between bytecode instruction ranges and machine code ranges, and various other information. This metadata was managed by CodeGenFixups, a member of the singleton MCGenerator class. All of the data in CodeGenFixups was specific to the current translation, so with this commit we moved it from what was effectively global data to something that was created and destroyed as needed by each thread. We also renamed it to CGMeta in the process, to more accurately reflect what it contained (the name CodeGenFixups was vestigial from when it contained nothing but the fixups member).
Code Cache
HPHP::jit::CodeCache is the C++ class responsible for managing the Translation Cache (TC), where we store code compiled by the JIT. While there is only one TC per process, it is not used in the same way by all translations. The range of memory managed by CodeCache is split into five blocks: hot, main, prof, cold, and frozen, and the code in each translation is split among three of those five blocks, depending on how hot the code is and which stage of compilation we’re running. We used to change state inside the global CodeCache to abstract away these changes, so the getters for each block would return different values depending on how the CodeCache had been configured. This worked, but was messy, and eventually led to things like functions named CodeCache::realMain() for when certain parts of the JIT needed the “real” main code block, not the one activated for the current translation.
To manage this particular piece of global state, we added CodeCache::View. Now, the getters on CodeCache always return the block matching their name. Any code that needs to emit code to a custom set of blocks calls CodeCache::view(), and uses the functions on the returned object, rather that the ones directly on CodeCache.
ProfData
The final data structure worth calling out is HPHP::jit::ProfData. ProfData contains all of the metadata used by our profile-guided optimizations, and needs to be efficiently accessed by many threads at once, both while running in the JIT and executing the compiled code. A single lock around the whole data structure would be easy but would cause too much contention. Instead, we handled each data member separately, using data structures like HPHP::AtomicVector or folly::AtomicHashMap as appropriate.
Throwing the Switch
After cleaning up all of the relevant global state and coarse locking, we were ready to turn on the concurrent JIT compiler in production. One minor tweak before doing so was refining the RuntimeOption used to enable it. This allowed us to concurrently compile profiling translations, where code layout is less important, while still using the write lease to ensure a good layout for the minority of code that doesn’t make it through the PGO pipeline.
The primary benefit we were hoping to see was improved behavior during server startup. Without concurrent JIT compilation enabled, HHVM will fall back to the interpreter when it wants to compile some code but another thread is already running in the JIT. In deployments like facebook.com, where we have a very large PHP codebase and many threads running at once, this means we’ll waste a lot of CPU cycles in the interpreter while a single JIT thread works to compile any code needed by the the requests being served. Enabling concurrent JIT compilation allows more compiled code to be ready sooner, getting other request threads out of the interpreter and saving CPU cycles. These charts illustrate the point very clearly:
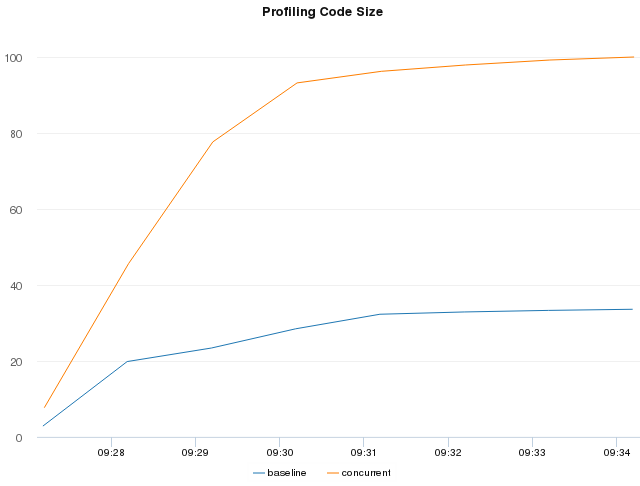
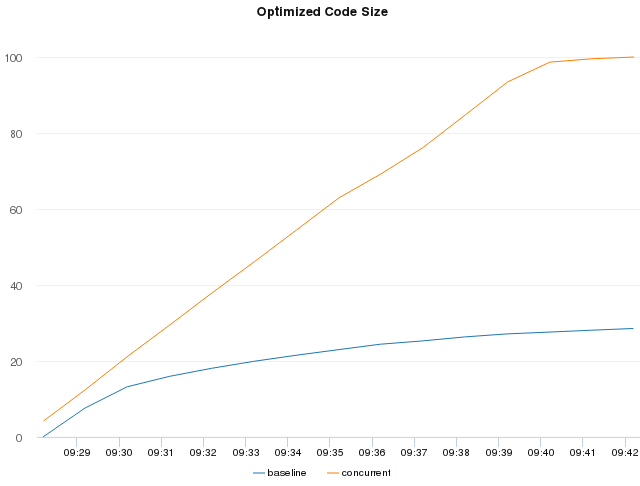
As you can see, the concurrent machines generate significantly more code in the same amount of time compared to the baseline machines. The extra code is because the faster code generation process lets us profile and optimize more functions before hitting various configurable limits in our PGO pipeline.
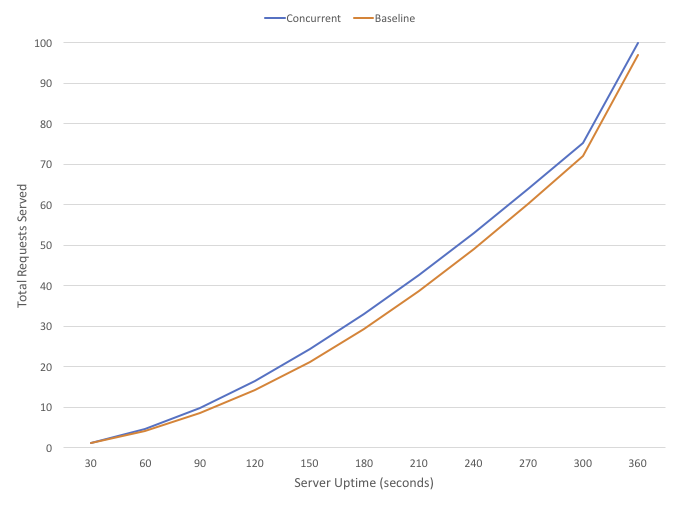
The next chart shows another metric we used to measure the impact of this change: total requests served since server startup, with CPU utilization held constant across all test machines. The chart focuses on the first six minutes of uptime, where the effect is most pronounced. Between 90 and 180 seconds of uptime, the concurrent test machines served about 15% more requests than the baseline machines.
Looking Forward
The work described here is not the end of this road. We already have work in progress to build more sophisticated warmup strategies, including optimizing all profiled functions at once using a pool of worker threads, rather than using the request thread that happens to hit the profiling threshold. We have another post about these efforts in the pipeline, so check back here every few weeks if this kind of work interests you!