
How the Cyber-Elephant Got His ARM
HHVM is now fully-functional on ARM hardware! This post tells the story of how our ARM port came to be.
In the High and Far-Off Times the Cyber-Elephant, O Best Beloved, had no ARM. He had only a bulgy x86-64 backend, as big as a boot (for a CISC has many instructions), that he could wriggle about from side to side; but he couldn’t pick up things with it. But there was one Cyber-Elephant—a new Cyber-Elephant—a Cyber-Elephant’s Port—who was full of ‘satiable curiosity, and that means he asked ever so many questions.
The Elephant’s Question: Can HHVM run on AArch64?
Answer: It can now! Let me tell you all about it.
(NB: This post accompanies a talk given at Linaro Connect Budapest 2017, which you can watch here.)
The Beginning of the ARMadillos
In the very middle of those times was a Stickly-Prickly HHVM, and it looked like this:
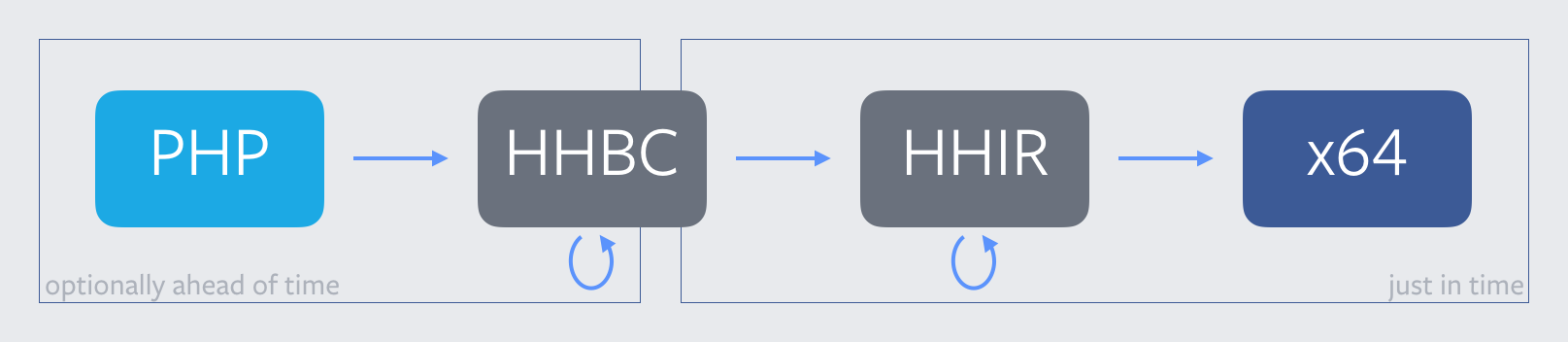
This is roughly how our compiler pipeline was architected when HHVM first started investigating a port to AArch64. (For more background on this picture, take a look at The Journey of a Thousand Bytecodes.) The HHVM team’s initial foray into ARM was a largely internal, proof-of-concept effort, and we hacked it up in classic Facebook fashion. Rather than trying to wrestle with build toolchains or early-stage hardware, we compiled AArch64 code on x64 machines using vixl. Then, we used the vixl simulator to execute that code. This was obviously not a perfect arrangement—we couldn’t exercise the code at the boundary between native and jitted code, nor test code smashing. And, of course, all of our C++ runtime functions were still compiled and run on x64 as usual. But it did let us test out lowering HHIR to AArch64, which gave us this picture:
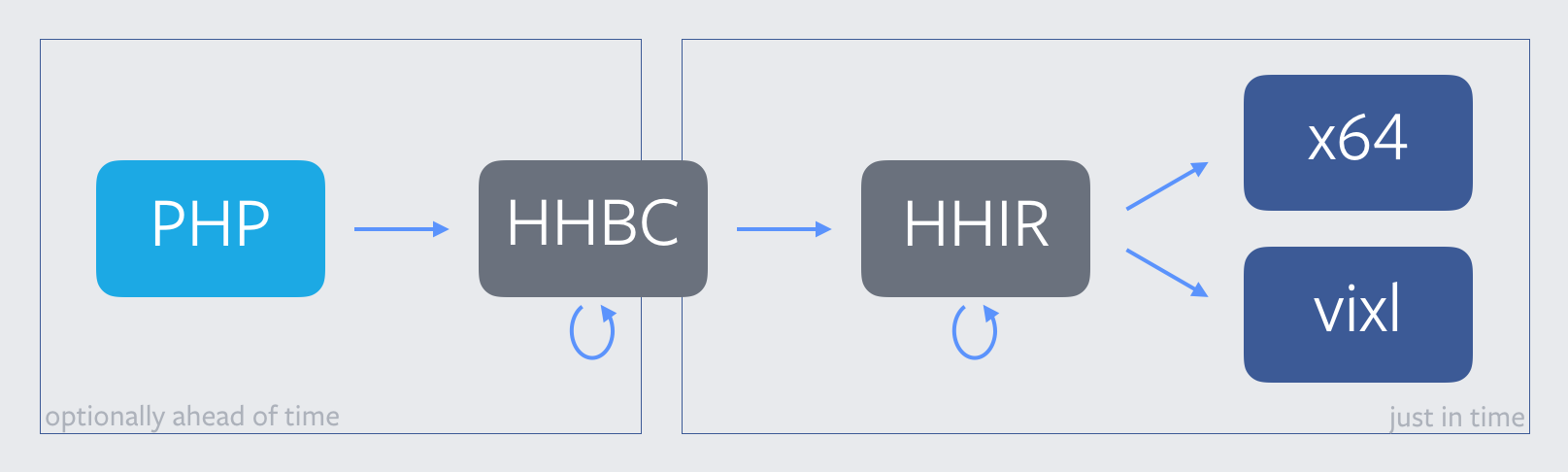
Unfortunately, and perhaps unsurprisingly, the maintenance burden of having two lowering targets for each HHIR instruction caught up to us quickly. With over 600 opcodes in its instruction set today, HHIR does not easily admit multiple backends. Furthermore, as the middle-end of our compiler, HHIR is frequently in flux. HHVM engineers routinely create new HHIR opcodes, or modify existing ones, to accommodate new language features or to make performance improvements. Having to write two essentially identical implementations for so many IR opcodes—with one in an assembly language that was foreign to most of our engineers—was a hassle which started to slow down our development.
Our team did have continuous integration testing for the ARM simulator, which,
in theory, would keep us honest and prevent us from regressing. However, as we
entered our regular performance sprints, we would often leave behind a trail of
PUNT()s in the ARM-lowering routines for new HHIR opcodes. These PUNT()s
would cause HHVM to fall back to the interpreter whenever those opcodes were
executed. While this did preserve correctness, it violated the spirit of our
porting effort: to take an earnest stab at compiling to and running AArch64 in
HHVM’s JIT.
Around the time the simulator started becoming seriously burdensome, we were also starting to experiment with LLVM. While those efforts did not persist in the compiler pipeline we have in HHVM today, we did learn helpful lessons about supporting additional backend targets. We also built up a lot of infrastructure to facilitate such experiments, at the heart of which was vasm, or “virtual assembly”: a low-level, close-to-the-metal intermediate representation which sat just atop the machine code:

Vasm began its life as a thin wrapper around x64 assembly, and even today, it bears a truly uncanny resemblance. But the LLVM port required us to create appropriate abstractions and higher-level vasm instructions—around smashable calls, native-to-jitted code ABI boundaries, and x64 peculiarities like idiv—to permit lowering to LLIR. These turned out to be the right abstractions, and they ultimately paved the way for the compiler pipeline we have today:
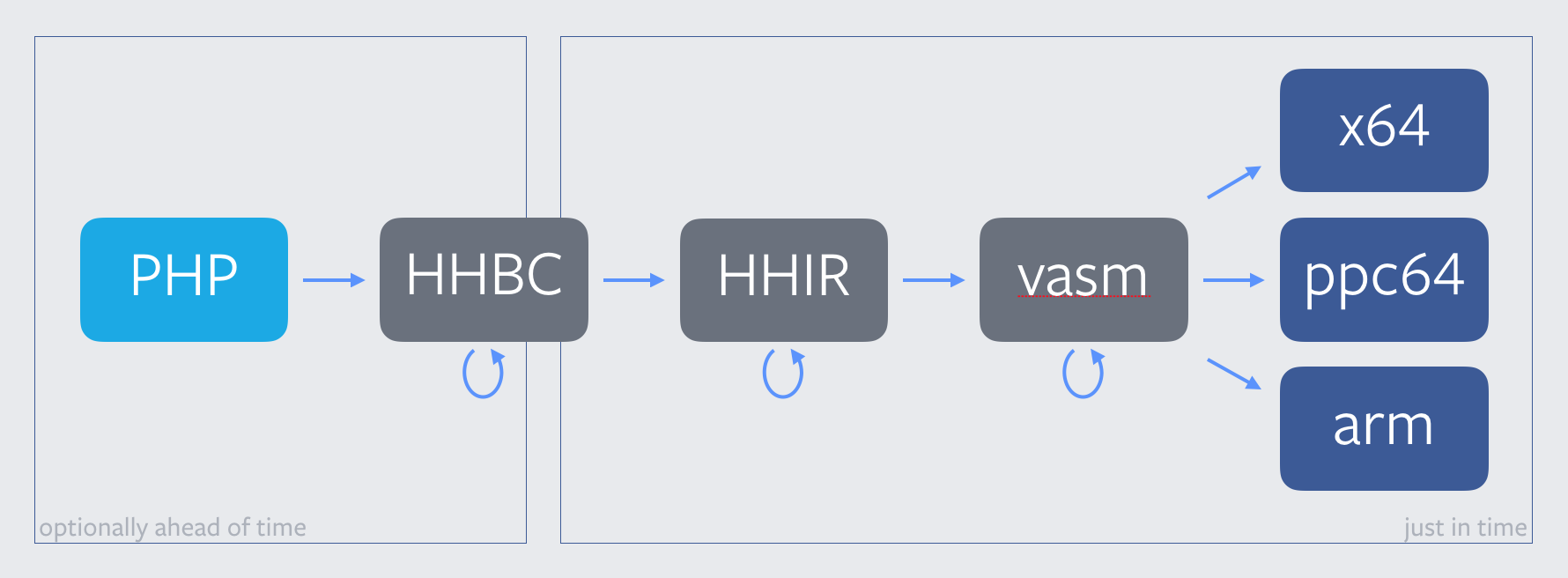
(Oh, perhaps in my zeal to tell a fanciful story about a Cyber-Elephant, I may have forgotten to mention—HHVM now runs on PowerPC, too!)
Cast of Contributors
Of course, the most important component of any story is its characters, and the characters in this story are the developers in the ARM community who made this port possible. Among the major ARM port contributors are:
- Lakshmi Pathy (@lpathy)
- Dave Estes (@dave-estes)
- Jim Saxman (@jim-saxman)
- Christoph Müllner (@cmuellner)
- Steve Walk (@swalk-cavium)
- Andrew Pinski (@apinski-cavium)
These engineers, from various ARM vendor companies and other organizations in the ARM ecosystem, have been collaborating and digging deep into the guts of HHVM since late 2015. Their work has brought HHVM from a bitrotting ARM simulator to a system which can compile and run PHP and Hack code, right now, on any law-abiding ARM machine.
How the ARM Port Was Made
In order to attain baseline functionality of the JIT, these developers had to take on the following:
- Lower each (sometimes underspecified) vasm instruction to AArch64 machine code.
- Manage alignment, synchronization, and cache line tearing for HHVM’s code smashing mechanisms.
- Navigate boundary-crossing between C++ and jitted code, and ensure adherence to HHVM’s (sometimes underspecified) translation cache (TC) ABI.
- Identify and debug portability issues in C++ code across the system.
But these engineers have done work that goes well beyond correctness. They’ve also implemented a number of nontrivial optimizations, including:
- Strength reduction on flag-setting instructions. On x64, arithmetic and bitwise operations always set the status flags, but this is not the case on ARM. With some better analysis of defs and uses of virtual SF registers, we can avoid unnecessary flag-setting on ARM (and other architectures with multiple strengths of arithmetic instructions).
- 64-bit immediate lifting. Since all instructions on AArch64 are exactly 4 bytes long, 64-bit immediates can’t be encoded as part of the instruction (unlike on x64, where such encoding is straightforward). Local analysis in vasm allows us to materialize in registers any large immediates that are used multiple times around a given code locus. This lets us avoid some redundant construction of 64-bit immediates, without substantively increasing register pressure across the compilation unit.
- Branch offset optimization. Immediate offsets in AArch64 branch instructions are restricted to 26 bits (64 MiB) for unconditional jumps or 19 bits (0.5 MiB) for conditional jumps. When initially lowering vasm, we are position-agnostic, and need to be conservative around jumps to, e.g., jitted helper stubs. HHVM has a facility for compile-time code relocation, which we now leverage in the ARM port to strength-reduce conservatively generated indirect branches whenever possible.
Our developer community has even set up CI testing for the ARM port!
Ultimately, we were able to achieve these results thanks to two major factors. The first is years of slow-but-steady iteration on our architecture and toughening of our abstractions and APIs. This work greatly reduced the technical surface area that a new backend target would need to touch. The second is the ARM community’s commitment to the HHVM project specifically, but also to compatibility of open source software with their platforms more generally. Their expertise expedited our ARM port’s development, and their collaboration with our team exemplifies the benefits gained from open-sourcing a piece of technology.
Future Work
HHVM may be up and running on AArch64, but there’s still plenty of work left to do.
One area for optimization that we suspect may be particularly fruitful lies in code size and layout. Cache is king, and HHVM has long been sensitive to code layout and the consequent cache effects. On ARM, where instruction sequences tend to be longer (both in bytes and in instruction count) than on x64 for the same operations, instruction cache effects are even more pronounced. Some ideas for exploration include:
- Use 2MB pages for hot functions in .text, and try out larger page sizes for jitted code.
- Leverage post-compile-time dynamic code relocation to shrink already-smashed jump sequences in jitted code.
- Interleave main and cold code sections in the TC to avoid indirect jumps due to large offsets.
- Align jump targets.
- Implement more peephole passes to reduce jitted code size.
Beyond that, we want to do more profiling of PHP open source workloads on ARM
machines using the Linux perf tool, or our own TC-print profiling tools for
HHVM. There also remain a few edge-case discrepancies in behavior on ARM vs.
on x64—due to differences in configuration, package dependencies, third-party
libraries, and the like—which we will eventually nix.
If you’d like to join in the work on the ARM port, or just stay up-to-date on our progress, feel free to subscribe to the mailing list for the ARM effort. And, as always, please post on HHVM’s Facebook group, or contact us on IRC in #hhvm-dev on Freenode with any questions you might have.